
La diffusione dei TV ad alta definizione ha portato ad un progressivo e sempre più rapido incremento della risoluzione. Dagli HD Ready, generalmente caratterizzati da una risoluzione di 1366 x 768 pixel, si è poi passati ai Full HD (1920 x 1080 pixel) e agli Ultra HD (3840 x 2160 pixel). L’ultima e più recente novità è costituita dai televisori con risoluzione 8K, 7680 x 4320 pixel, una densità estremamente elevata che richiede, come ad ogni passaggio, un adeguamento di tutta la catena video, dalla produzione alla distribuzione dei contenuti.
Come avviene in occasione di ogni incremento quantitativo dei pixel, la diffusione degli schermi precede quella del materiale a risoluzione nativa. Lo abbiamo sperimentato fin dagli albori dell’HD e lo possiamo constatare anche oggi: la maggior parte dei canali sul digitale terrestre trasmette ancora segnali in Standard Definition (SD). É proprio per questo motivo che alcune tecnologie integrate nei TV risultano fondamentali per poter garantire una buona qualità con tutte le tipologie di segnale. Ci riferiamo a tutto ciò che normalmente viene definito “upscaling“, il processo compiuto dall’elettronica per adattare le sorgenti alla risoluzione del pannello (se le due non combaciano già in partenza, naturalmente).
Questo aspetto risulta particolarmente importante sui TV 8K per via della disponibilità di materiale a risoluzione nativa. La recentissima introduzione sul mercato dei primi esemplari (parliamo degli ultimi due anni circa per i modelli consumer) rende imperativa la necessità di adattare al meglio tutto il materiale disponibile a risoluzione inferiore, dalla definizione standard alle varie forme di HD (come 720p, 1080i e 1080p) passando poi per l’Ultra HD. Per eseguire questo adattamento nel miglior modo possibile sono nate nuove soluzioni più evolute rispetto ai sistemi che potremmo definire più convenzionali. Nel corso dell’articolo andremo ad illustrare le tecnologie messe in campo da Samsung per l’upscaling sui TV QLED 8K.
SOMMARIO
COME VIENE GESTITA LA RISOLUZIONE SUI TV PIATTI

Tutti i TV piatti dispongono di una risoluzione nativa che potremmo definire una misura d’area espressa in pixel anziché in centimetri. La più comune è ormai da tempo l’Ultra HD, 3840 x 2160 pixel alla quale si aggiungono anche altre varianti più o meno definite. Ci riferiamo a tutto quello che rientra sotto il cappello dell’HD-Ready, generalmente fissato a 1366 x 768 pixel (ormai presente solo su tagli piccoli di fascia bassa), al Full HD, 1920 x 1080 pixel e all’8K, 7680 x 4320 pixel.
Tutto ciò che viene visualizzato su schermo viene sempre riadattato alla risoluzione nativa del pannello (ovviamente nel caso non lo sia all’origine). Non importa dunque che si utilizzino i sintonizzatori integrati per il digitale terrestre o satellitare, un lettore Blu-ray o Ultra HD Blu-ray, una console o PC da gioco o lo streaming tramite le applicazioni per Smart TV; in tutti i casi è l’elettronica a compiere le operazioni necessarie per “spalmare” i pixel presenti nella sorgente su tutti quelli messi a disposizione dallo schermo.
Senza questo processo sarebbe possibile visualizzare immagini a tutto schermo solo nel caso in cui la risoluzione del segnale in ingresso fosse perfettamente sovrapponibile con quella del pannello. Tutte le sorgenti con definizione più bassa verrebbero semplicemente mostrate all’interno di una finestra grande una frazione dello schermo: le dimensioni diverrebbero sempre più piccole in proporzione al calo della risoluzione. Basti pensare, ad esempio, che un TV Full HD dispone di 2.073.600 pixel contro i 414.720 pixel di una sorgente PAL a definizione standard. Se non ci fosse alcuna operazione per riadattare la risoluzione, il video PAL in ingresso occuperebbe solo 1/5 del display.
COS’É L’UPSCALING E COME FUNZIONA

L’upscaling è l’elaborazione che si applica tutti i segnali meno definiti per portarli alla risoluzione nativa di un TV. Il processo inverso (da un segnale più definito ad un pannello meno definito) si chiama invece downscaling. A svolgere tutti i calcoli necessari è l’elettronica di bordo, meglio identificata come “processore video”. La bontà dell’adattamento varia in funzione delle tecnologie impiegate.
La forma più basilare di upscaling è fondata sull’interpolazione, un calcolo matematico che permette di determinare alcuni valori non noti conoscendo altre informazioni collegate all’interno dello stesso intervallo. L’interpolazione viene usata sui televisori per vari scopi: si può applicare ad esempio per incrementare la fluidità delle immagini creando nuovi fotogrammi che si aggiungono a quelli presenti nella sorgente. In questo caso i fotogrammi originari sono le informazioni note che consentono di elaborare (nell’intervallo tra due frame) i movimenti intermedi necessari a rendere più scorrevoli i filmati.

Quando si parla di upscaling l’interpolazione è di fatto il meccanismo più elementare che può essere applicato. Ne esistono comunque delle varianti più o meno complesse che permettono di ottenere risultati differenti. La logica è sempre la stessa: le immagini vengono ricostruite ragionando in base ai colori contenuti nel segnale da upscalare. Il modello utilizzato si basa sulle informazioni relative ai colori presenti nella sorgente originale: i pixel mancanti vengono rappresentati su schermo replicando lo stesso colore presente nel pixel più vicino del quale si conosce l’informazione cromatica (poiché è presente nel segnale a risoluzione inferiore).
Questi calcoli si possono anche applicare in modo più raffinato e complesso per ottenere risultati migliori. Ne sono un esempio l’interpolazione bilineare e l’interpolazione bicubica. La prima aumenta il numero di pixel usati come modello per ricostruire quello mancante: l’elettronica analizza i colori presenti sui 4 pixel più prossimi (disposti su una griglia 2 x 2) e ricrea una componente cromatica che risulta una media tra tutti i valori di partenza. L’interpolazione bicubica opera invece analizzando i 16 pixel più vicini disposti su una griglia 4 x 4.
Esistono perciò varie soluzioni e algoritmi capaci di produrre risultati più o meno buoni e con un “peso”, inteso come capacità di calcolo necessaria, molto differente. Nel corso degli anni tutte le tecnologie hanno dovuto fare i conti con aumenti progressivi ed importanti della risoluzione di tutti gli schermi televisivi, dei monitor e dei proiettori. Questi incrementi hanno evidenziato varie limitazioni che tratteremo nel prossimo capitolo.
I LIMITI DELL’UPSCALING CONVENZIONALE

L’upscaling basato sull’interpolazione va incontro a diversi limiti che non vengono superati nemmeno con le versioni più sofisticate dei già menzionati algoritmi. L’efficacia limitata era già nota ed apprezzabile sin dall’introduzione sul mercato dei primi pannelli ad alta definizione. É proprio per questi motivi che anche gli algoritmi si sono evoluti col tempo. La disponibilità di schermi sempre più definiti ha semplicemente accentuato tali problemi e ha reso evidente la necessità di compiere un ulteriore passo in avanti.
Quali sono queste limitazioni? Come si può intuire non è semplice ricreare con precisione le informazioni mancanti basandosi semplicemente su quelle presenti all’interno dei pixel che compongono la sorgente da upsclare. Un primo esempio in tal senso è costituito dalle linee oblique. La ricostruzione dei pixel da creare ex-novo porta facilmente a far emergere quello che in gergo prende il nome di “aliasing“, un termine che si può rendere in italiano con “scalettature“. Quelle che dovrebbero risultare semplicemente linee perfettamente dritte sono invece strisce di pixel disposti a zig-zag. L’occhio le percepisce come una sorta di tratti incerti e poco definiti.
L’incremento della risoluzione e con essa del livello di dettaglio porta poi spesso ad aumentare anche il rumore video eventualmente presente nella sorgente. Per contenere questi difetti sono stati sviluppati appositi algoritmi che però vanno incontro ad ulteriori criticità, prima tra tutte la necessità di bilanciare l’intervento per non risultare troppo aggressivi. La riduzione del rumore video, se applicata con troppa enfasi, porta infatti a mitigarne sensibilmente l’incidenza ma a discapito dei dettagli presenti su schermo. In pratica si tratta della proverbiale coperta corta: incrementare molto la risoluzione può portare ad esaltare il rumore video e contenere quest’ultimo causa una diminuzione del dettaglio (quanto meno di quello più fine).
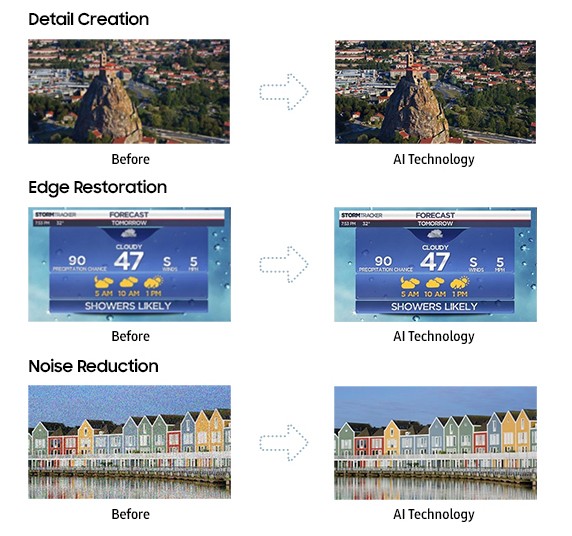
Un altro artefatto ricorrente è il cosiddetto “edge enhancement“, un ispessimento dei bordi che si verifica proprio perché l’elettronica, approssimandone la ricostruzione, non riesce sempre a definire esattamente i contorni e finisce per copiarli su una quantità di pixel eccessiva enfatizzandoli più del dovuto. Lo si può notare di sovente anche sul testo scritto che, proprio per questo motivo, appare più sgranato e più difficoltoso da leggere. Per mitigare tutti i limiti che abbiamo descritto si può ricorrere all’uso di alcuni filtri che rendono più morbida l’immagine, in modo da mascherare i difetti presenti. Il prezzo da pagare è rappresentato da un quadro che appare più sfocato e piatto.
In generale possiamo pertanto affermare che gli algoritmi convenzionali hanno un’efficacia non sempre ottimale poiché si basano su modelli generici che non consentono di ottimizzare gli interventi agendo in maniera specifica sull’immagine. Ne deriva una ricostruzione del dettaglio non sempre efficace specialmente quando la mole di informazioni mancanti da ricreare è ingente, come nel caso dei segnali a risoluzione più elevata, 8K su tutti. Sono questi i motivi che hanno portato alla creazione di tecnologie capaci di portare l’upscaling su di un livello più elevato.
IL CONTRIBUTO DELL’INTELLIGENZA ARTIFICIALE
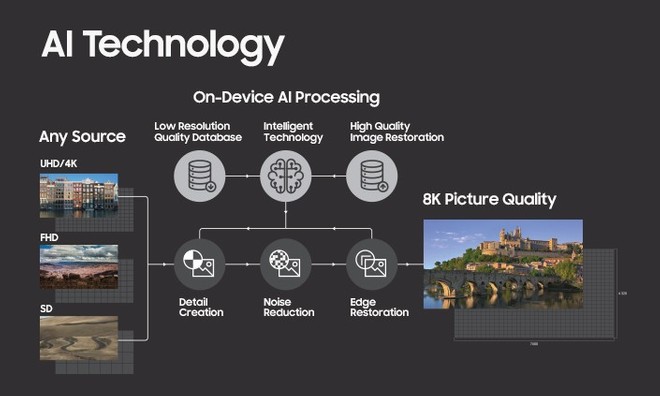
Come abbiamo visto i modelli tradizionali si sono rivelati limitati nell’adattare la risoluzione dei contenuti a schermi sempre più definiti. Il motivo è del resto facilmente intuibile: la quantità di pixel da ricreare quando si porta un segnale SD, HD o Full HD su un televisore 8K è estremamente elevata. Basarsi solo su un’approssimazione che prende in considerazione i pixel più vicini non è un sistema efficace perché non permette di ricostruire un livello di dettaglio soddisfacente. Tutti i particolari che renderebbero l’immagine più compatta, tridimensionale e ricca si vanno irrimediabilmente a perdere inficiando tutti i vantaggi dati dall’altissima definizione dei pannelli.
Qual è stata dunque la soluzione verso cui si sono affacciati i produttori che hanno scelto di puntare sui televisori 8K? La risposta alle necessità summenzionate è l’intelligenza artificiale, una soluzione che Samsung ha adottato (tra i primi nel mercato TV) sin dalla prima generazione introdotta nel 2018. Cosa si intende realmente con “intelligenza artificiale”? Questi termini, insieme all’acronimo AI (o IA se lo si traduce più propriamente in italiano) sono divenuti ormai di uso molto comune non solo nel trattamento di segnali video ma anche per molti altri ambiti.

All’ampio uso non è però corrisposto una altrettanto diffusa opera di divulgazione utile per far comprendere meglio la natura di questo concetto che per molti è rimasto sicuramente fumoso. Non stupisce pertanto che molte persone associno l’intelligenza artificiale a “chiacchiere da marketing” che hanno il solo scopo di imbellettare i prodotti agli occhi dei potenziali clienti.
In realtà si tratta di una semplificazione che cela un argomento molto vasto e complesso che però è ben lontano dal poter essere definito “tutto fumo e niente arrosto”. L’intelligenza artificiale si basa sulle cosiddette reti neurali artificiali, un modello di calcolo la cui struttura stratificata cerca di imitare la rete di neuroni nel cervello umano. Robert Hecht-Nielsen, un pioniere nel settore dei neurocomputer, le ha definite così:
Un sistema di elaborazione costituito da una serie di elementi semplici e altamente interconnessi, che processano le informazioni mediante la loro risposta di stato dinamica agli input esterni.
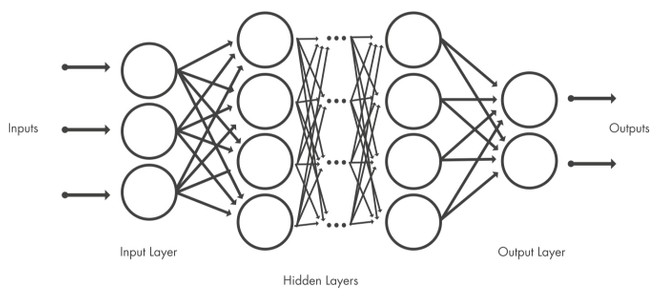
Le reti neurali sono costituite da un certo numero di nodi interconnessi e sono organizzate in strati. Il sistema più basilare è quello che prevede un livello di input, un livello di output e uno strato nascosto (hidden layer). Il livello di input è quello iniziale: è qui che gli input esterni vengono presentati alla rete sotto forma di modelli. Tramite l’interconnessione fornita dai nodi, che potremmo definire come neuroni artificiali, si passa poi al livello nascosto dove viene eseguita l’elaborazione vera e propria. Il livello di output è quello che fornisce il risultato di tutto il processo. Questa spiegazione molto semplificata ci permette di passare al vero fulcro del discorso: come funziona in concreto una rete neurale e quali vantaggi offre?
Nel caso dell’upscaling di segnali video si parte da un archivio composto da immagini campione preparate da tecnici. Il contributo umano è necessario anche per impostare le caratteristiche da ricercare nelle immagini e i classificatori in base a cui l’AI deve poi operare; non è quindi un automatismo assoluto. Su queste premesse la rete neurale inizia ad apprendere in base ai criteri impartiti sfruttando quello che viene definito machine learning. Samsung lo ha integrato nelle prime generazioni di televisori 8K, nello specifico le serie Q900R e Q950R.
L’archivio predisposto dagli ingegneri coreani contiene immagini in alta e bassa definizione che servono per allenare l’intellingenza artificiale. Questa dicotomia è fondamentale perché permette di valutare quanto dettaglio viene perso scalando verso il basso e come peggiora la qualità. In pratica si opera prima degradando la qualità, passando da un’immagine in alta risoluzione ad una sua versione meno definita, dopodiché si inverte l’elaborazione per insegnare all’AI come ripristinare tutte le informazioni perse. Il confronto tra le due versioni innesca il processo utile a riconoscere ed applicare gli interventi più efficaci per eseguire un upscaling a risoluzione 8K. Questo processo viene affinato gradualmente con ripetute iterazioni e permette di migliorare la qualità dell’elaborazione.

A differenza della semplice interpolazione dei pixel, la rete neurale è in grado di scegliere come intervenire in base a vari elementi, quelli che sono stati impostati nelle fasi iniziali dai tecnici. Il sistema può riconoscere elementi come volti, superfici particolari (le trame di un tessuto oppure una parete in pietra), un testo eccetera e applica a ciascuno gli algoritmi più efficienti utilizzando l’approccio che ha portato al miglior risultato in fase di apprendimento. Possiamo suddividere l’upscaling con machine learning nelle seguenti fasi:
- Il segnale in ingresso viene analizzato dal processore che lo confronta con il suo archivio, cercando per ogni elemento su schermo (volti, superfici eccetera) il modello più simile;
- Su ogni elemento vengono applicati gli algoritmi che hanno dato i risultati migliori per quel determinato oggetto;
- L’elaborazione comprende vari passaggi: ricostruzione del dettaglio originale (perso per via della risoluzione più bassa), riduzione del rumore video e miglioramento dei bordi di tutti gli oggetti.
La qualità dell’upscaling risulta sensibilmente migliore rispetto a quella che si ottiene tramite sistemi convenzionali. Il motivo è presto detto: l’interpolazione non è un metodo particolarmente raffinato e sicuramente non è “intelligente”. Non è infatti capace di operare distinzioni sugli elementi da elaborare e interviene perciò tendenzialmente sempre allo stesso modo. L’AI può invece riconoscere determinati oggetti: un volto ad esempio ma anche un palazzo, un prato o un tessuto. In tutti questi casi non viene semplicemente replicata l’informazione contenuta nei pixel contigui: il processore applica gli algoritmi che si sono dimostrati più efficaci per ogni modello che ha imparato a riconoscere, restituendo una resa il più vicino possibile a quella di un segnale a risoluzione nativa.
QUANTUM PROCESSOR 8K E AI UPSCALING: ARRIVA IL DEEP LEARNING

Con la terza generazione di TV 8K, lanciati nel 2020, Samsung ha introdotto il Quantum Processor 8K con AI Upscaling e deep learning. Dietro questa terminologia si cela una forma più evoluta di intelligenza artificiale capace di offrire vari vantaggi. A distinguere il deep learning dal machine learning è anzitutto la struttura della rete. Il termine “deep” fa riferimento agli strati nascosti che sono molteplici (si può arrivare a numeri molto elevati). Ogni livello di nodi si allena su un insieme distinto di parametri in base all’output del livello precedente. Si può dunque intuire la complessità di questo sistema che è capace di gestire archivi molto estesi e di operare sulla base di moltissimi parametri.
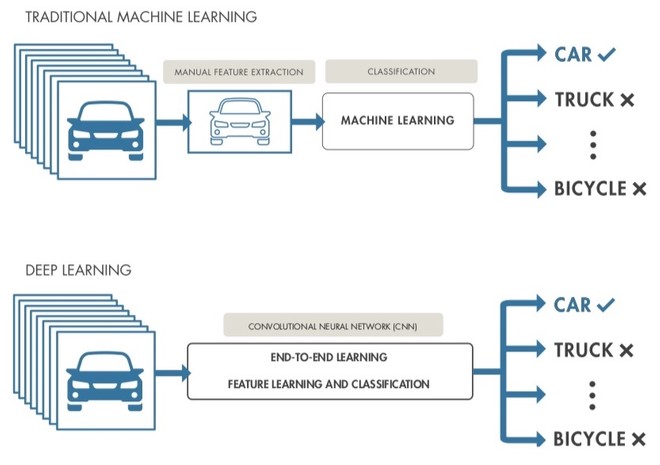
Il deep learning è anche in grado di raggruppare autonomamente i modelli inseriti come input per la rete neurale. Se il machine learning richiede che sia un’intelligenza umana a svolgere questo lavoro, il deep learning può invece operare in proprio ed è in grado di scoprire correlazioni all’interno di dati che non sono stati etichettati e strutturati, individuando anche criteri e somiglianze che potrebbero sfuggire all’intervento umano o che richiederebbero molto più tempo per essere catalogati. Nel caso di immagini l’AI può raggruppare tutto ciò che contiene una barca in primo piano, tutte le foto con un cane in alto a destra o tutte quelle dove compare sempre la stessa persona.
Durante il processo di apprendimento l’intelligenza artificiale con deep learning impara a riconoscere le correlazioni tra alcune caratteristiche rilevanti e i risultati ottimali. Ovviamente un tale livello di complessità e di finezza nell’elaborazione dei dati ha un costo: per poter funzionare al meglio è richiesta una maggiore capacità di calcolo e un archivio di partenza molto esteso. I benefici sono però molteplici: se il machine learning permette di applicare gli algoritmi per il miglioramento dell’upscaling nel modo più efficace, il deep learning può spingersi ancora oltre, arrivando ad ottimizzare e ad affinare gli algoritmi stessi. Questa caratteristica, tradotta in parole più semplici, permette al processore di sviluppare in proprio appositi algoritmi in base all’archivio usato per l’apprendimento dell’AI.
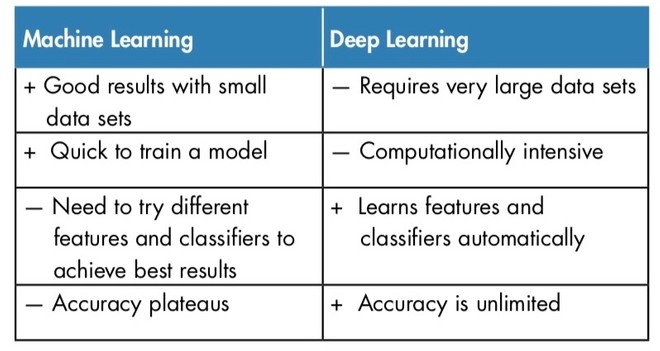
L’upscaling non è più limitato al riconoscimento di determinati elementi od oggetti impostati dall’uomo nelle fasi iniziali dell’elaborazione. Il processore è in grado di distinguere la tipologia dei contenuti che l’utente sta visualizzando sullo schermo: riesce quindi a capire il contesto. Lo sport, un film o un programma televisivo vengono trattati diversamente applicando le tecniche più efficienti per ogni scenario. L’intervento si può concentrare sulle aree più importanti dell’immagine mettendo in secondo piano le altre. Non sempre è consigliabile applicare determinate elaborazioni a tutto il quadro: nel caso in cui vi siano aree in cui il dettaglio è molto ridotto si corre il rischio di enfatizzare i difetti presenti (per esempio rumore video o sfumature imprecise). Differenziare il trattamento per concentrarsi dove è veramente utile previene queste problematiche che sarebbero invece emerse con un upscaling convenzionale.
A fare la differenza, rispetto al machine learning, non è dunque la natura degli interventi adottati: parliamo sempre di tecniche per ricostruire il dettaglio, per ridurre il rumore video, migliorare i bordi di oggetti, soggetti, testi e così via. L’incremento qualitativo è dato da un livello di ottimizzazione superiore: l’analisi delle immagini pixel per pixel trae giovamento dalla possibilità di stabilire molti più criteri (individuati dall’AI) per la classificazione degli elementi che compongono l’archivio di modelli. La rete neurale sfrutta tutte le correlazioni trovate per sviluppare gli algoritmi; l’apprendimento porta così a perfezionare l’upscaling e ad elevarne le prestazioni.
Articolo in collaborazione con Samsung



